Learning embodied agents with policy gradients to navigate in realistic environments
Indoor navigation is one of the main tasks in robotic systems. Most decisions in this area rely on ideal
agent coordinates and a pre-known room map. However, the high accuracy of indoor localization cannot be achieved in
realistic scenarios. For example, the GPS has low accuracy in the room; odometry often gives much noise for accurate
positioning, etc. In this paper, we conducted a study of the navigation problem in the realistic Habitat simulator.
We proposed a method based on the neural network approach and reinforcement learning that takes into account these factors.
The most promising recent approaches were DDPPO and ANM for agent control and DF-VO for localization, during the analysis
of which a new approach was developed. This method takes into account the non-determinism of the robot's actions and the
noise level of data from its sensors.
MIPT
HSE
MIPT
HSE
MIPT
References
Task formulation
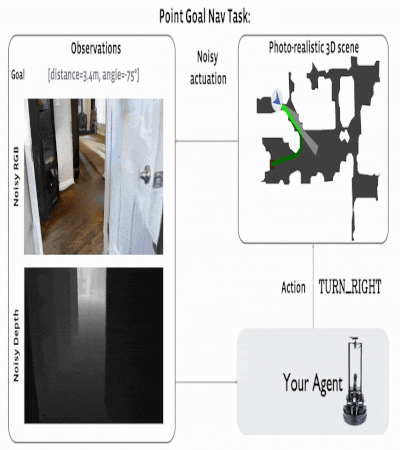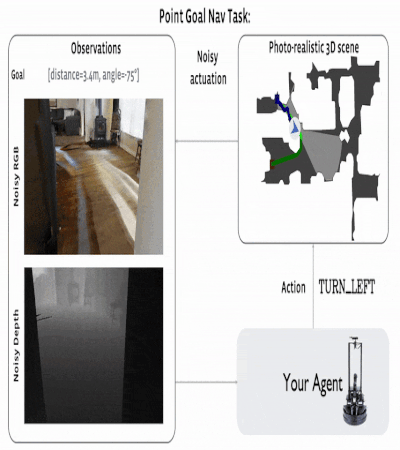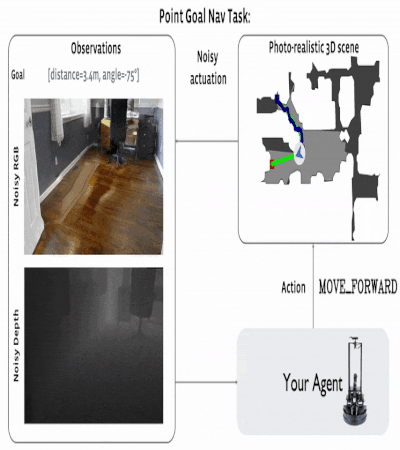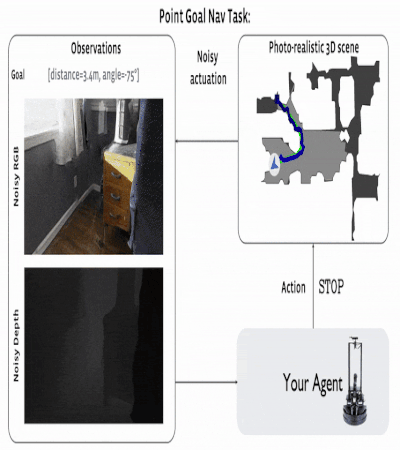
The navigating task to the given coordinates initializes the agent at a random place on the map. The goal is the
target coordinates, which are set as ("Go 5 m to the north, 3 m to the west relative to the beginning"). The room
map is not available to the agent, and during the evaluation process, the agent can only use the input from the
RGB-D camera for navigation.
The agent had four actions: forward, turn left, turn right, and stop. Evaluation occurs when the agent selects
the 'STOP' action. As a metric, SPL (Success weighted by Path Length) is used. The episode is
considered successful if, when calling 'STOP,' the agent is within 0.36 m (2x radius of the agent) from the
coordinates of the target.
Results
As the overall approach, we used DF-VO as a localization module and trained DDPPO with its coordinates. This approach gave us SPL around 0.32 in normal condtions and 0.16 in noisy conditions. We evaluated these results at ten different maps and took the average. The first experiment (zero pos) is to pass zero coordinates to DDPPO, the second experiment (ground truth pos) is to pass ideal coordinates from the environment to the DDPPO. For the RTAB-MAP, turn angle was reduced from 10 degrees to 5, since RTAB-MAP cannot track position with such a big difference between frames. With the presence of sensor noise, RTAB-MAP also fails, and output zero position at every step, but in good conditions outperform DF-VO by far. The main reason why both RTAB-MAP and DF-VO performance significantly worst than ground truth coordinates, it is hard to determine the final stopping place. Especially if the goal is near the wall, an agent could reconstruct the goal coordinates on the other side of the wall due to the localization error.
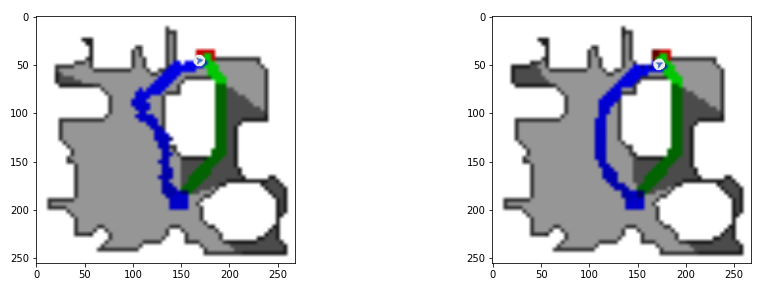
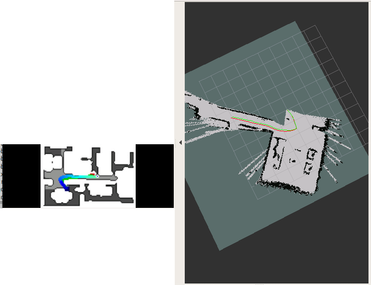
Example of DDPPO agent trajectory with ground truth pos. Left trajectory with action and sensors noise, right without. The green path is the ideal path with SPL=1; the blue path is a real agent path.
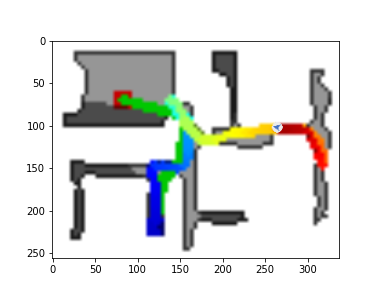
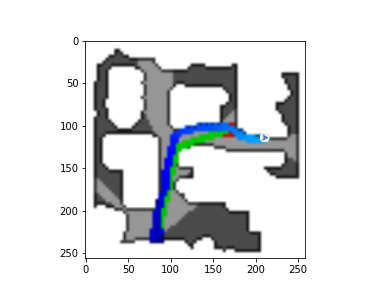
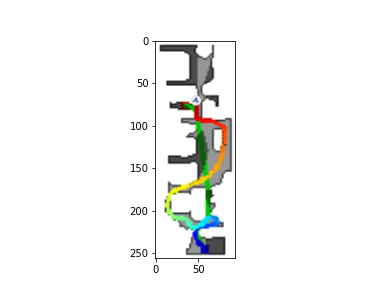
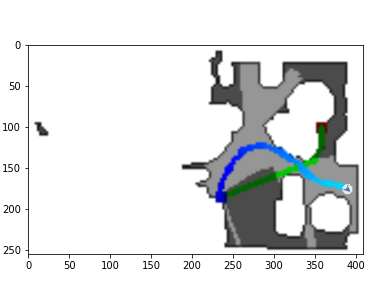
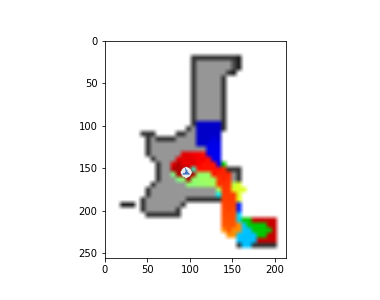
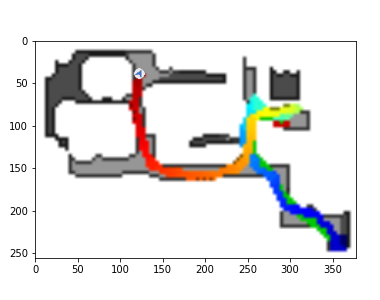
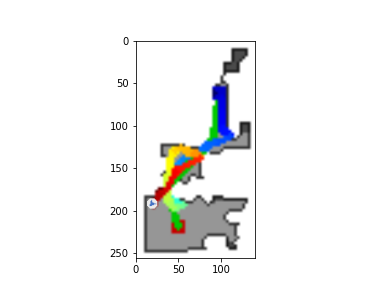
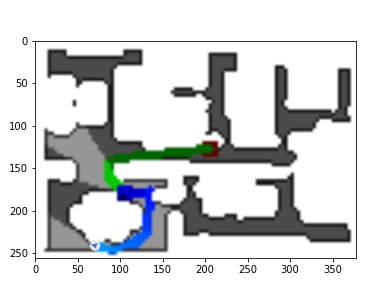

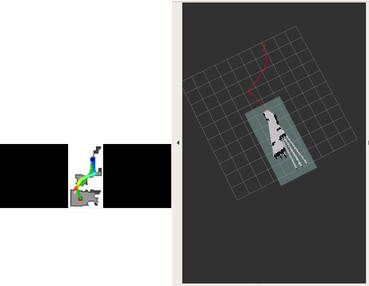
The DDPPO agents trajectories with zero pos. The green path is the ideal path with SPL=1; the blue path is a real agent path.
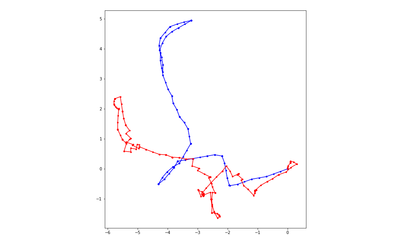
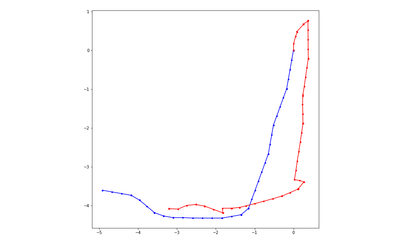
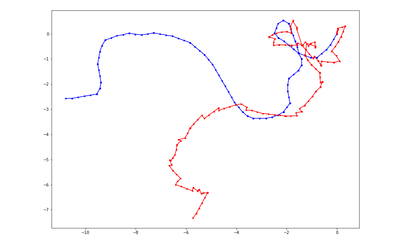

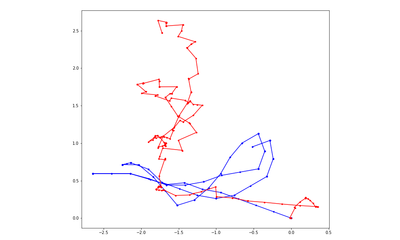
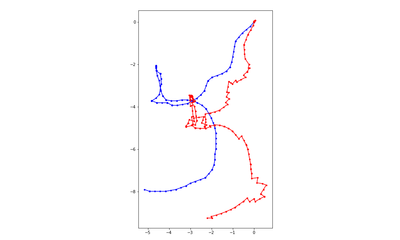
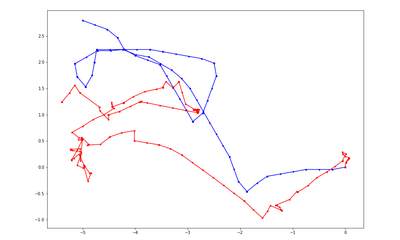
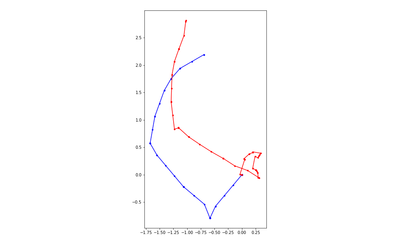
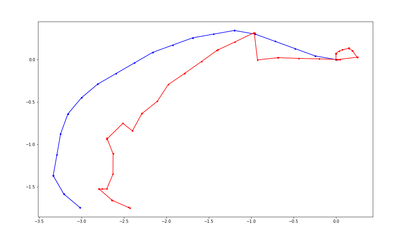
DDPPO results with DF-VO pos. The blue line is the ground truth trajectory. The red line is the DF-VO trajectory that passed to the DDPPO.
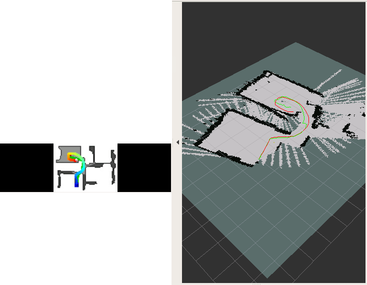

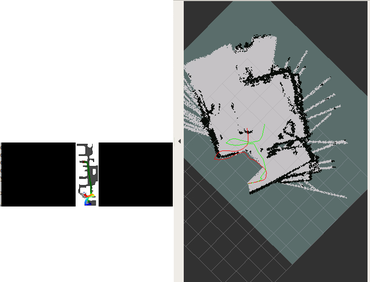
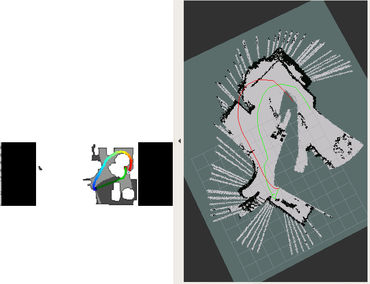
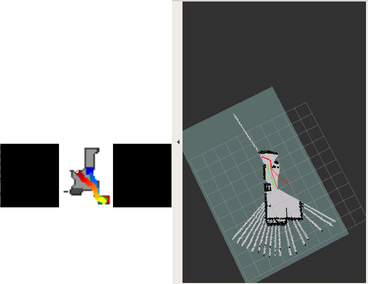
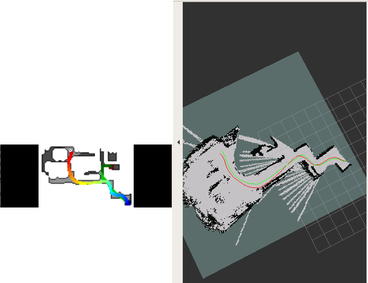
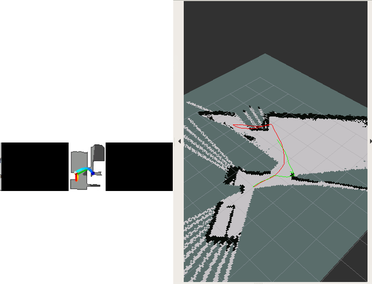
DDPPO results with RTAB-MAP pos. The red line is the ground truth trajectory. The green line is the RTAB-MAP trajectory that passed to the DDPPO.
Result table (SPL)
| Zero pos | Ground truth pos | RTAB-MAP pos | DF-VO pos | |
|---|---|---|---|---|
| Action and sensor noise | 0.08 | 0.58 | 0.09 | 0.16 |
| Sensor noise | 0.10 | 0.62 | 0.11 | 0.20 |
| Without noise | 0.13 | 0.72 | 0.40 | 0.27 |
Conclusion
Extensive work has been done to study and test modules for the RL agent in the Habitat environment. We trained the bunch of state of the art solutions for navigation and building maps on the premises and developed a solution for the point goal task. Focusing on the article DF-VO and DDPPO, we built a combination of these algorithms for the realistic noise conditions in the new Habitat environment. DF-VO was used to determine the position of the agent, which allowed us not to use ground truth coordinates from the environment, relying only on the RGB-D sensor. DDPPO was used to control the agent, relying on the reconstructed coordinates, and showed an excellent ability to adapt to all noises and imperfections of the environment. In the future, we plan to improve the overall performance and transfer the policy from a simulator to a real-world robot.